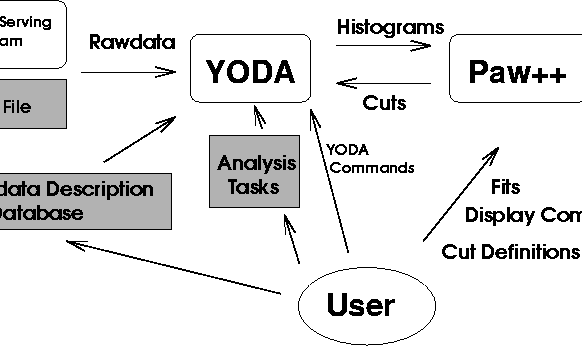
The simplified program structure is depicted in Figure 2.1. The YODA interpreter gets its data either directly from a file or from a data-serving program. This data-serving program can either be a formatter -- for data not yet in the expected YODA data format -- or e.g. a simulation program generating rawdata-looking events.
These two methods of input offers maximum flexibility. For the standard usage of YODA with input rawdata (typically written on a VME eventbuilder), the latter method is suitable, as it will be explained below.
Data processing is then done via analysis tasks written by the user for his special application. This is done in YODA's built-in interpretative language.
To provide convenient symbolic access to the data, the user has to create a database file, which describes the data coming in. Here, the user's knowledge about the experiment is put in. Once YODA gets the data in one of the ways described above, it reads them event-by-event (each event normally corresponds to one hardware trigger and readout of front-end electronics). For each event, it looks up pieces of information on how to handle the event data in the user-supplied database. Then, it looks for user analysis tasks which act on these data, makes the data available to the analysis tasks, and calls the analysis task for this special event. Data for which no database information exists or no user task waits for, is simply discarded. Thus, the user can just ''pick out'' the data he or she needs.
Histograms are produced by the user task. These are periodically transmitted to paw and are available there almost indistinguishable from ''normal'' paw histograms. By now, histogrammed results are also saved using PAW's histogram I/O.
One can further use paw to define graphical cuts interactively. This will be explained in more detail in a later section.
As already mentioned in the introduction, there is also the possibility to enhance YODA via a programming interface (this is not shown in figure 2.1). When this approach is chosen, there is also the possibility to generate new events from inside YODA, or use YODA to a filter events, i.e. accept or reject events according to certain criteria and write them to file again. Details can be found in section 7.2.